Playing around with fast.ai text API.
I scraped Edogawa Ranpo (江戸川乱歩) novels from aozora bunko (青空文庫).
Scraping aozora bunko was the most difficult part.
Fastai supports many useful utils out of the box. For example,
from fastai import *
from fastai.text import *
this already added the requests library in scope.
This time I'm also using beautiful soup for html parsing so I'm going to import that too.
from bs4 import BeautifulSoup
Now I'm getting the top page of aozora bunko where they list all the links to the novel pages by Edogawa.
base_path = "https://www.aozora.gr.jp/"
page = requests.get(base_path + "index_pages/person1779.html")
I'm using beautiful soup to
soup = BeautifulSoup(page.text, 'html')
texts = []
for a in soup.find_all("a"):
href = a.get("href")
if isinstance(href, str) and href.startswith("../cards"):
tmp_path = base_path + "/".join(href.split("/")[1:])
tmp_page = requests.get(tmp_path)
tmp_soup = BeautifulSoup(tmp_page.text, "html.parser")
for tmp_a in tmp_soup.find_all("a"):
tmp_href = tmp_a.get("href")
if (
isinstance(tmp_href, str) and
tmp_href.startswith("./files") and
tmp_href.endswith(".html")
):
source_path = "/".join(tmp_path.split("/")[:-1] + [tmp_href[2:]])
source_page = requests.get(source_path)
source_page.encoding = "shift-jis"
source_soup = BeautifulSoup(source_page.text, "html.parser")
text = (
source_soup
.find("div", {"class": "main_text"})
.text
.strip()
.replace("\n", "")
.replace("\r", "")
.replace("\u3000", "")
)
texts.append(text)
Finally I cut up the novels by the periods ("。") and store them into a pandas dataframe.
splitted_texts = [ts + "。" for t in texts for ts in t.split("。")]
df = pd.DataFrame(splitted_texts).drop_duplicates().reset_index(drop=True)
Then comes the fast.ai part. First, I create a MeCab based tokenizer that extends fast.ai's BaseTokenizer class to perform tokenization on Japanese texts.
Edit: 12/1/2019
mecab-python3 is currently not actively maintained.
natto-py is the recommended module for mecab python wrapper.
from natto import MeCab
nm = MeCab()
class MeCabTokenizer(BaseTokenizer):
def __init__(self, lang:str): self.lang = 'ja'
def add_special_cases(self, toks:Collection[str]): pass
def tokenizer(self,raw_sentence): return [node.surface for node in nm.parse(raw_sentence, as_nodes=True)]
Then I'll use the tokenizer and set up a databunch object using the TextList input class. This is basically how fast.ai treats data within their api.
tokenizer = Tokenizer(MeCabTokenizer, 'ja')
processor = [TokenizeProcessor(tokenizer=tokenizer), NumericalizeProcessor(max_vocab=60000,min_freq=2)]
data_lm = (
TextList
.from_df(df,Path("data"),cols=[0],processor=processor)
.split_by_rand_pct(0.1)
.label_for_lm()
.databunch(bs=64)
)
data_lm.show_batch()
| idx | text |
|---|---|
| 0 | 歩い て い まし た 。 xxbos 三 人 とも 、 小学校 三 年生 の なかよし です 。 xxbos 「 あらっ 。 xxbos 」 サト子 ちゃん が 、 なに を 見 た の か 、 ぎょっと し た よう に たちどまり まし た 。 xxbos ミドリ ちゃん も サユリ ちゃん も びっくり し て 、 サト子 ちゃん の 見つめ て いる 方 を ながめ まし た 。 xxbos する と |
| 1 | やって来 た の です よ 。 xxbos 例 の カフェ・アトランチス の 件 で 至急 に 会い たい という の です 。 xxbos 態 々 ( わざわざ ) こんな ところ まで 追っかけ て くる 程 だ から 、 恐らく 何 か 大きな 手掛り を 掴ん だ の でしょ う 。 xxbos あの 手紙 を 白紙 と すり 換え た 奴 が 分っ た かも 知れ ませ ん 」 「 それ は |
| 2 | 部屋 の 奥 の 方 に 、 何者 か が 深夜 の 会合 を し て いる の で は ある まい か 。 xxbos xxunk 共 か 。 xxbos まさか xxunk そんな もの が 、 人里 近い この 辺 に xxunk で いる 筈 も ない 。 xxbos で は 、 山 の 奥 から さまよい 出し た 谺 ( こだま ) の 精 、 老樹 の 精 、 |
| 3 | いる 。 xxbos だ が 、 君 の 口 から 詳しい 話 が 聞き たい もん だ ね 」 「 無論 話す が ね 。 xxbos それ より も 、 ここ に いい もの が ある ん だ 。 xxbos 僕 個人 の 捜査 日記 だ よ 。 xxbos 君 に 読ん で 貰お う と 思っ て 持っ て 来 た の だ 。 xxbos 口 で 云う より |
| 4 | なかっ た 。 xxbos 彼 は 寝床 から 手 を 伸し て 、 窓 の 戸 を 半分 だけ 開け て 置い て 、 蒲団 ( ふとん ) の 中 に 腹ばい に なっ た まま 、 煙草 を 吸い 始め た 。 xxbos 「 昨夜 ( ゆうべ ) は 、 己 ( おれ ) は ちと どうか し て い た わい 。 xxbos 安来 節 が 過ぎ た |
That's it! I can create a model and feed this object in. So first I create a model:
learn = language_model_learner(data_lm, AWD_LSTM, pretrained=False)
Find the optimal learning rate:
learn.lr_find()
learn.recorder.plot()
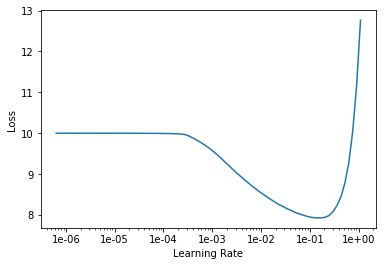
And fit.
learn.unfreeze()
learn.fit_one_cycle(16, 1e-02)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 4.507823 | 4.334403 | 0.316128 | 01:38 |
| 1 | 3.803796 | 3.680052 | 0.382662 | 01:39 |
| 2 | 3.522720 | 3.444266 | 0.403864 | 01:39 |
| 3 | 3.423434 | 3.347921 | 0.411120 | 01:39 |
| 4 | 3.347341 | 3.291305 | 0.417679 | 01:39 |
| 5 | 3.279663 | 3.247730 | 0.423628 | 01:39 |
| 6 | 3.216730 | 3.208911 | 0.426489 | 01:39 |
| 7 | 3.138893 | 3.176067 | 0.431173 | 01:39 |
| 8 | 3.067047 | 3.145211 | 0.436084 | 01:39 |
| 9 | 2.992936 | 3.113955 | 0.440698 | 01:39 |
| 10 | 2.916804 | 3.091572 | 0.444655 | 01:39 |
| 11 | 2.840940 | 3.072649 | 0.447346 | 01:39 |
| 12 | 2.766437 | 3.061572 | 0.449103 | 01:39 |
| 13 | 2.705637 | 3.056961 | 0.450885 | 01:39 |
| 14 | 2.663790 | 3.055644 | 0.451035 | 01:39 |
| 15 | 2.642250 | 3.056106 | 0.450893 | 01:39 |
Now I can generate novels in Edogawa Ranpo fashion.
learn.predict("二十面相", n_words=50)
'二十面相 は おち なく て も 、 ポスト の ばけ もの は 、 どこ へ あらわ れ た の か 、 けん とう も つき ませ ん 。 xxbos 克彦 は 、 三谷 青年 の 腕 を 降り て 家 を 出 た が 、 まもなく 一 週間 も たっ た'
Easy to export:
learn.export("edogawa.pkl")
Next time I'll just load the learner using load_learner method:
learner = load_learner(path="models", file="edogawa.pkl")